表形式のデータが pdf フォーマットで配布される、というのはよくある事。
pdf形式というのは閲覧するだけならばかなり便利なのだけれど、その表のデータをスプレッドシートに読み込んでゴニョゴニョしたいときなどには不便です。
Ubuntuであれば、
- コマンド pdftotext で、pdfファイルからテキストを抽出して保存。
- テキストファイルを適宜加工してcsv形式に。
という方法が、いちばんシンプルにできそうです。
まぁ一口に「PDFフォーマットの表」といってもそれはそれは千差万別なので、2) の "適宜加工" というのは機械的にできるものではなく、完全に個別対応になってしまうと思います。
一例として、愛知県が連日発表している新型コロナウイルスの発生事例のpdfファイルをcsv形式に変換してみる。
上記ページから "県内発生事例一覧(x月x日現在)[PDFファイル/xxxKB]" というファイルをダウンロードして、aichi.pdf という名前で保存します。
元のpdfファイルの中身はこんな感じ。
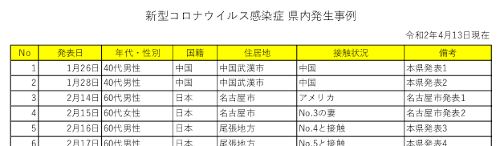
これを、pdftotext を使って aichi.txt というファイルに書き出し。
pdftotextに -layout オプションをつけて、元のレイアウトをできる限りそのままに書き出してみます。書き出された aichi.txt を開いて確認してみると以下のような具合。
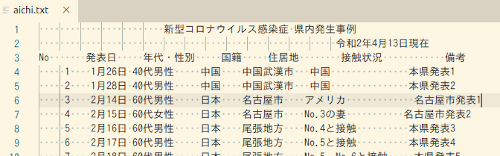
レイアウトもなかなか良い感じに保持されたまま、テキスト抽出に成功しています。
で、ここから、
…などなど、データを扱いやすいように加工して、出来上がった aichi.csv は以下。

加工は手作業でガシガシやっても良いし、正規表現を駆使してスパっとやっても良いのです。
もしコマンド pdftotext がインストールされていない! と言われてしまったら、
で、インストールしてみてください。
csvファイルが完成したらこっちのもの。データの取り扱いの幅がぐんと広がります。データを集計して、こんなグラフを作ってみたり。→ 新型コロナウイルス 愛知県のグラフ - freefielder.jp





コメント